山东手机报订阅方式:
移动用户发送短信SD到10658000
联通用户发送短信SD到106558000678
电信用户发送短信SD到106597009
大众网
|

海报新闻

大众网官方微信

大众网官方微博

时政公众号爆三样

大众海蓝

大众网论坛

山东手机报
山东手机报订阅方式:
移动用户发送短信SD到10658000
联通用户发送短信SD到106558000678
电信用户发送短信SD到106597009
2021
大众报业・大众网
手机查看
近日,AI顶级学术会议IJCAI 2021(人工智能国际联合会议,InternationalJointConferenceonArtificialIntelligence)发布了论文录用结果。
网易伏羲共有三篇论文入选,内容涵盖强化学习、虚拟人、图形图像等多个方向。文中提及的自动编舞、拟人行为算法、说话人脸视频合成等AI技术,能够广泛应用在文创产业,有效提高生产效率,优化用户体验。
IJCAI始于1969年,每年举办一次,是学术界和产业界极负盛名的AI会议,代表了国际前沿的科研水平。本届IJCAI将于今年8月在以蒙特利尔为主题的虚拟现实中举行。延续了上一年严格的审稿标准,IJCAI 2021论文接收率低至13.9%,在4204篇投稿论文中,仅有587篇被录取。
以下是网易伏羲本次入选的论文亮点:
1、《从音乐到舞蹈:游戏内角色的自动编舞》
(Automatic Translation of Music-to-Dance for In-Game Characters)
音乐舞蹈是近年来角色扮演类游戏中广受玩家喜爱的一个功能。此前,业内普遍将音乐舞蹈生成的问题看作是基于时序数据的受监督动作合成问题。不过,应用这类方法生成舞蹈,需要大规模有标注的训练数据作为基础,同时生成动作的质量常常不可控。
对此,网易伏羲提出了一个新的思路――用舞蹈专家视角来看待音乐舞蹈问题。团队首次尝试将传统舞蹈理论建模,即在逐片段的舞蹈动作检索框架下实现了自动编舞。基于上述设计,玩家可以在算法的基础上进一步编辑舞蹈动作,实现了以往被忽略的交互功能。
考虑到舞蹈动作所需的动作捕捉技术成本较高,且需要专业的舞者进行指导,因此,团队进一步使用了自监督训练方法,大大减少了对监督数据的依赖,降低了训练成本。
目前,论文中提及的算法已在《天谕》手游的舞者系统中落地,为玩家带去了极富创造性和观赏性的游戏体验。

《天谕》手游编舞玩法
2、《奖赏约束的行为克隆》
(Reward-Constrained Behavior Cloning)
深度强化学习技术已经在很多游戏中成功应用。但是,在强化学习的过程中,AI可能会因为种种原因学习到一些奇怪的“不类人”行为,这些行为可能会对游戏玩家的体验带来很大影响。例如,在自动驾驶任务中,如果以速度最快为奖赏,AI在行驶过程中可能会有许多的突然刹车和起步以及一些多余的小幅度变向,导致乘坐体验不佳,而这通常是人类驾驶员不会有的行为。
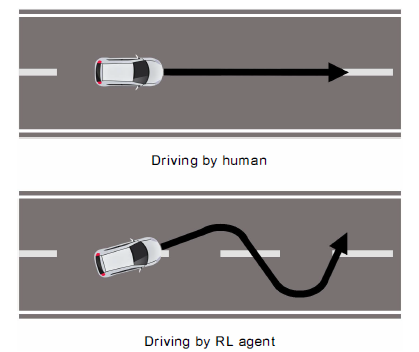
通过强化学习训练出来的自动驾驶AI行驶过程可能会有多余的小幅变向
为了克服这个问题,本文提出了一种在奖赏约束下的行为克隆训练方法(RCBC)。该方法综合了模仿学习和带有约束的强化学习训练方法,在最大化达到目标的同时,尽量通过人类示范数据学习类人的行为,兼顾学习目标的达成和行为过程的类人程度。

使用本文方法学习出的自动驾驶AI在保持较高速度的同时驾驶过程会更平稳(横坐标:时间,纵坐标:方向盘旋转角度,本文方法对应的蓝色曲线的车辆转向角度波动会更小
在实验部分,本文首先在一个简单的GridWorld环境中验证了RCBC可以通过调整超参的数值,来达到学习出不同拟人化程度策略的目的。进一步的,在基于MuJoCo的单摆和双摆环境中,RCBC可以在保持最终奖励值不降低的情况下,将学习到人类示范中行为模式所需的训练时间缩短约20%~50%。最后,在更复杂的自动驾驶模拟环境中(TROCS),RCBC可以在达到103km/h速度的情况下(对比算法最快速度109km/h),极大地提高驾驶过程的平稳程度。
3、《Audio2Head:声音驱动的一键式说话人脸视频生成器》
(Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion)
网易伏羲的研究旨在通过任意一张人脸图像和任意一段语音,合成口型同步、头动自然、表情自然的人脸说话视频。
此前,基于神经网络的算法已经使人脸视频的口型能够较好的与语音匹配,但仍存在头动不够自然、视频不连贯、存在大量伪影等问题。为解决上述问题,伏羲团队对头动单独建模,提出基于空间编码的神经网络进行自然的头动序列预测。为了对语音相关的整张图像的运动进行建模,伏羲团队提出了使用语音先驱动生成整幅图的稠密运动场,再由稠密运动场引导图像合成。
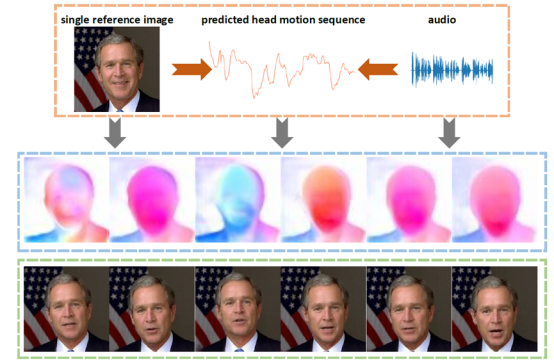
由算法合成的人脸说话视频
大量的实验结果证明,网易伏羲提出的方法可以让人脸视频的头动显得自然,并且与语音节奏保持一致,极大地提升了one-shot说话人脸视频生成研究的效果。据悉,该技术应用范围十分广泛,可用于虚拟助手、智能客服、新闻播报、远程会议、电子游戏等多个领域。
初审编辑:
责任编辑:何泉峰